
在前一篇博客 全干工程师的自我修养 前后端一体的启动模板 里介绍了自己搭建的启动模板。在这个 模板项目 中引入了 GraphQL 作为中间层。本文是对自己的学习过程做一个总结,如果理解错误或者不到位的地方,欢迎各位小伙伴指正、交流。
GraphQL 及其担任的角色
GraphQL 简介
在正式动手前,先大致了解一下 GraphQL。引用官网上的介绍:
GraphQL 既是一种用于 API 的查询语言也是一个满足你数据查询的运行时。 GraphQL 对你的 API 中的数据提供了一套易于理解的完整描述,使得客户端能够准确地获得它需要的数据,而且没有任何冗余,也让 API 更容易地随着时间推移而演进,还能用于构建强大的开发者工具。
在形式上我们可以简单地理解为,前端编写 SQL 请求向服务端查询或操作数据,返回的数据格式、字段都是由前端来决定的。
在前后两端中的角色
在微服务的架构中,GraphQL 可以承担 BFF 的角色来减少前端的请求次数。曾经碰到过一个没有做整合的项目,所有的请求都在前端做,一次又一次的用 id 查详情然后整合,简直就是噩梦……在 GraphQL 出现之前,一般会使用 Node.js 来做这一层。

在一般的单服务架构中,GraphQL 可以取代 Controller 层,来处理业务相关的逻辑。尽可能地保持 DAO 层的简洁。
而在客户端所担任的角色可以与 Axios 一样,即作为一个发送请求的工具。在 React 里面 Apollo Client 还提供了 Hooks 的实现。
搭建 GraphQL Plaground
GraphQL 不绑定数据库并且有各个语言的实现。这里使用 Apollo Server 作为示例。照着官网的示例,我们能很轻松地启动一个 GraphQL Server。
安装依赖
1
| npm install apollo-server graphql
|
编写 GraphQL Server: index.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| const { ApolloServer, gql } = require('apollo-server')
const typeDefs = gql`
type Book{
title: String
author: String
}
type Query {
books: [Book]
}
`
const resolvers = {
Query: {
books: () => books,
}
};
let books = [
{
title: 'Harry Potter and the Chamber of Secrets',
author: 'J.K. Rowling',
},
{
title: 'Jurassic Park',
author: 'Michael Crichton',
},
];
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});
|
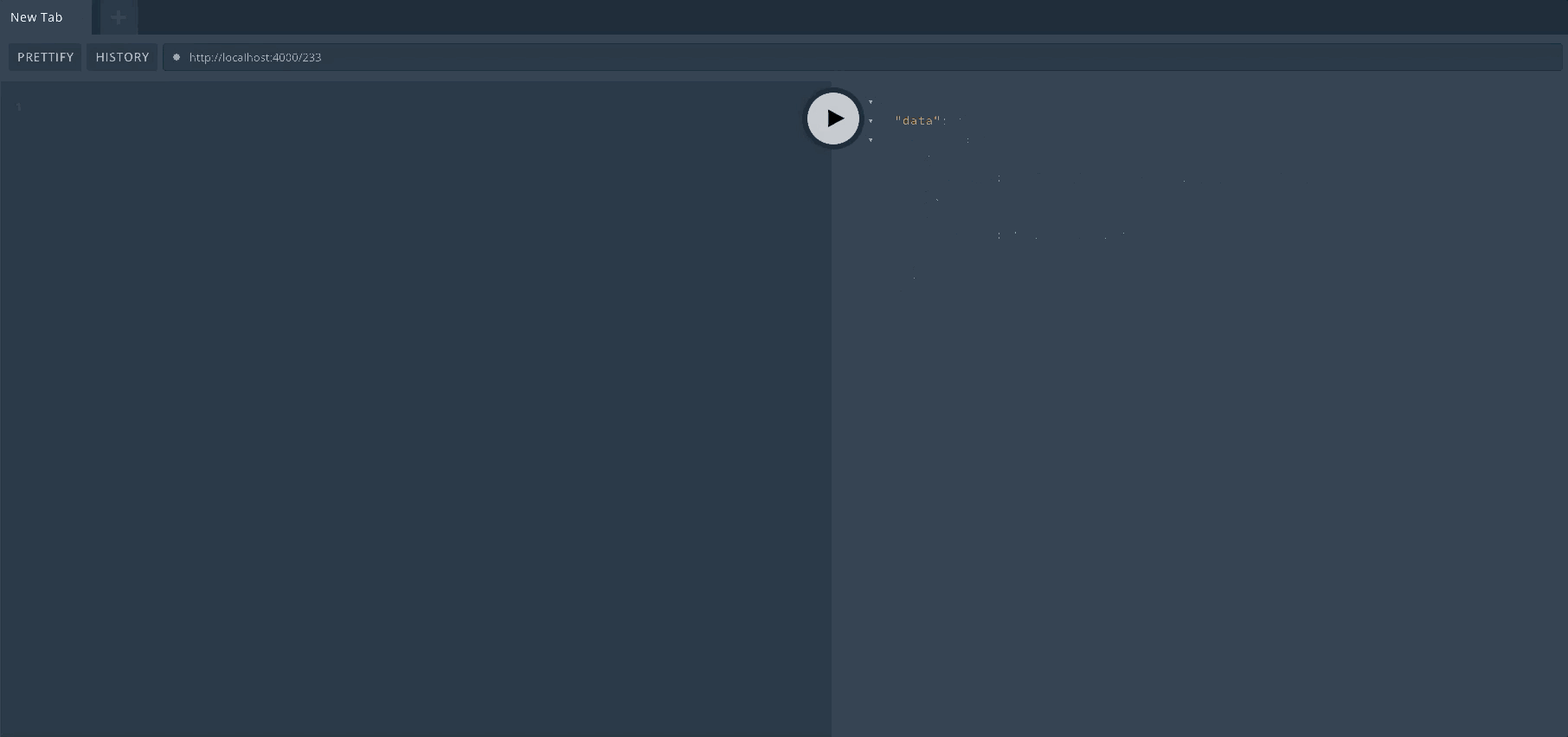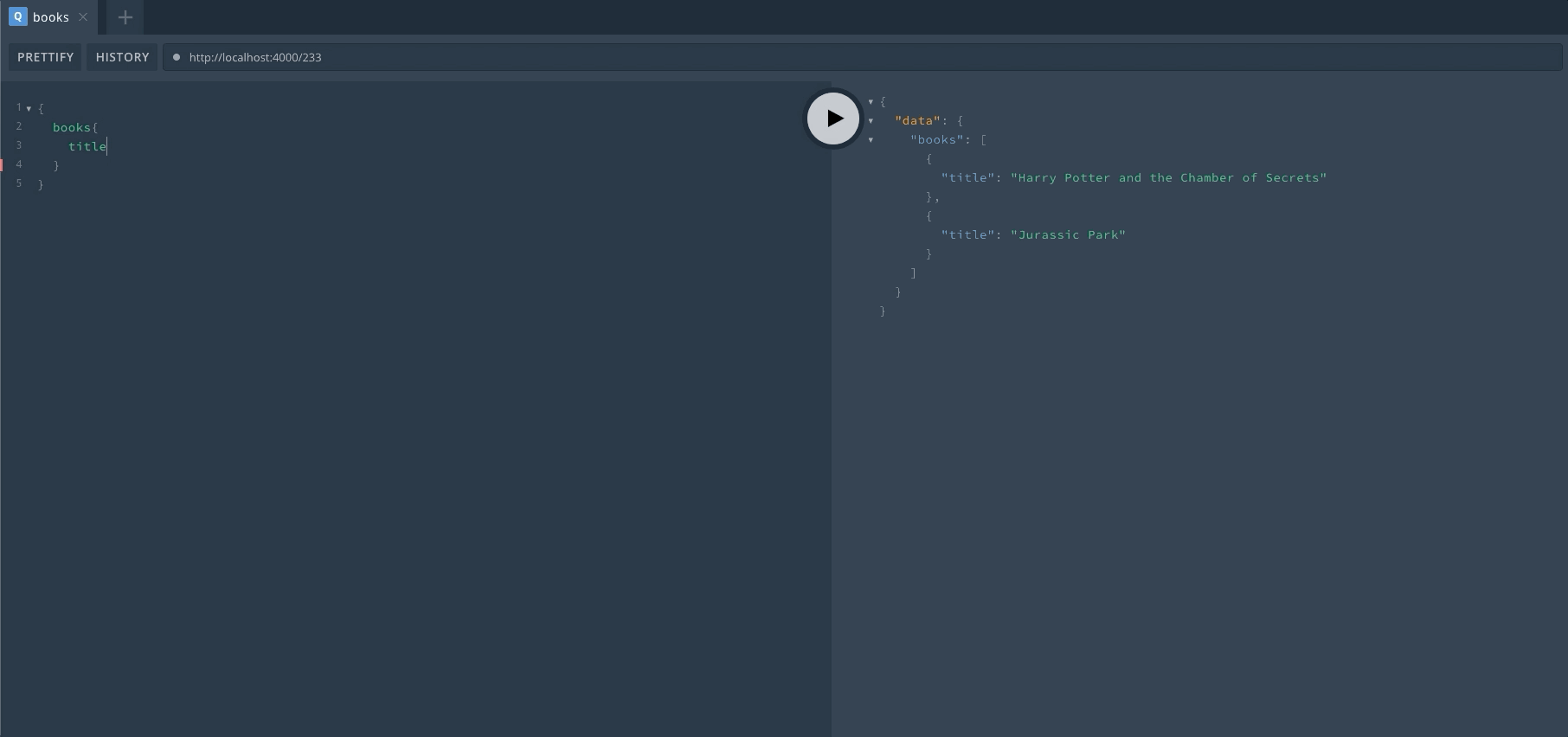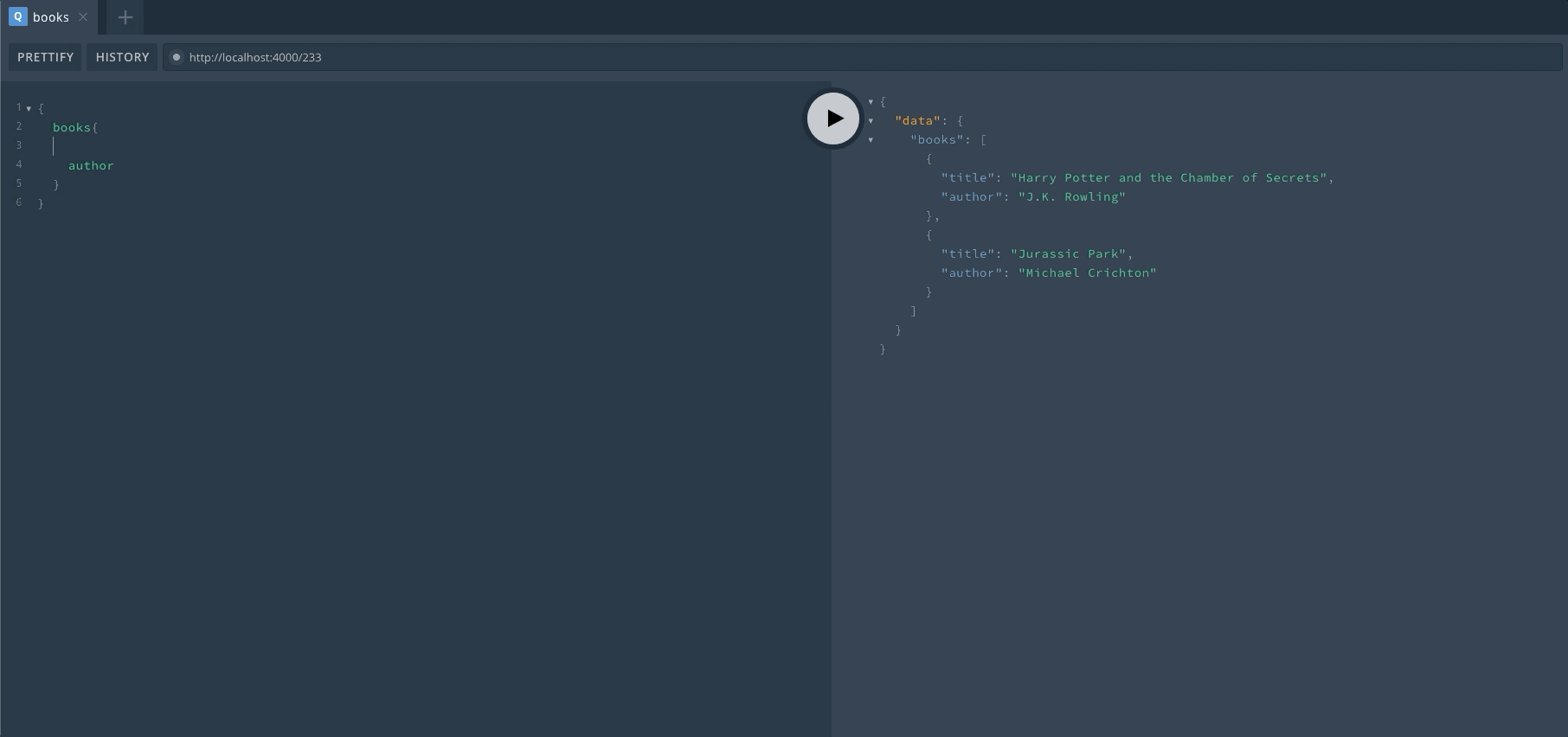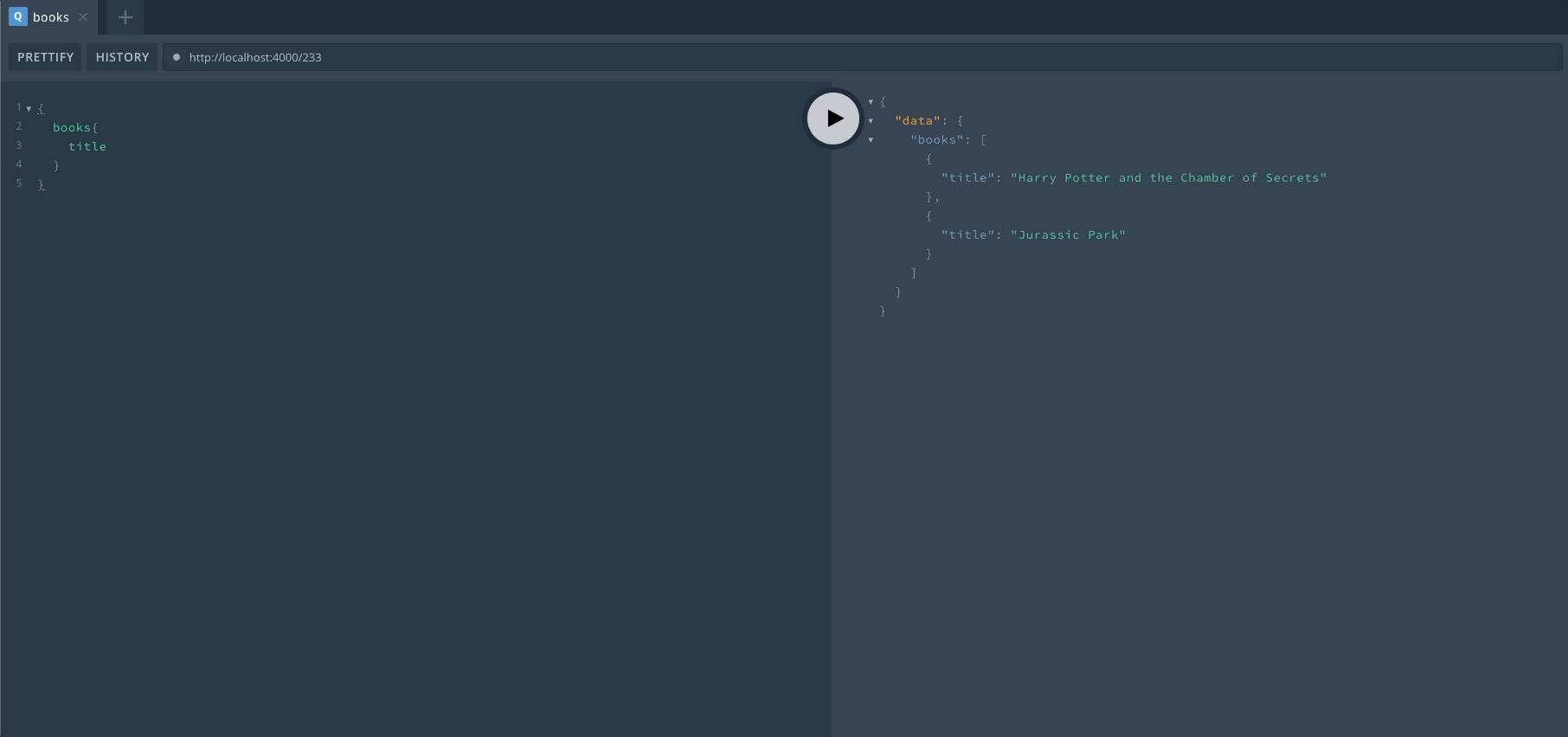
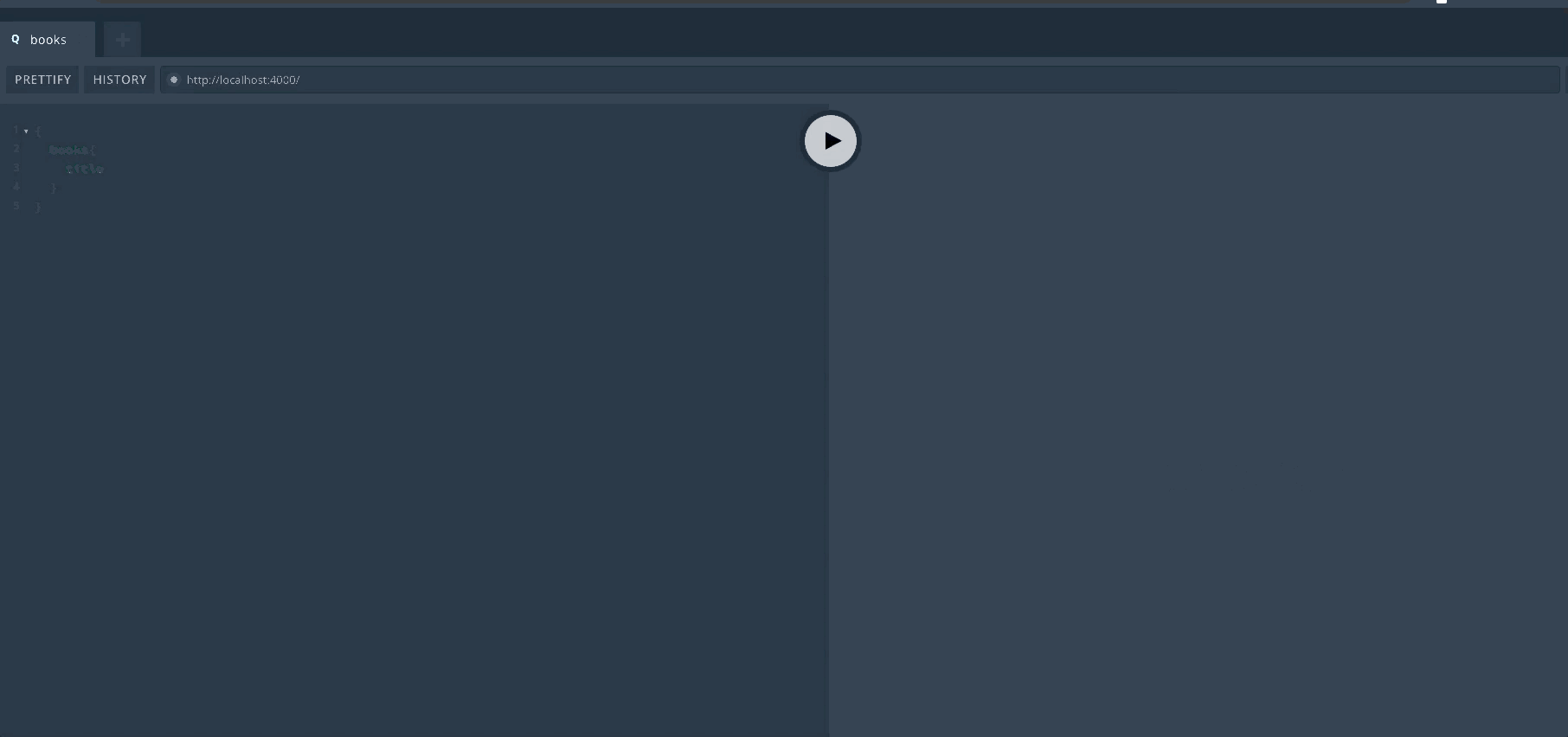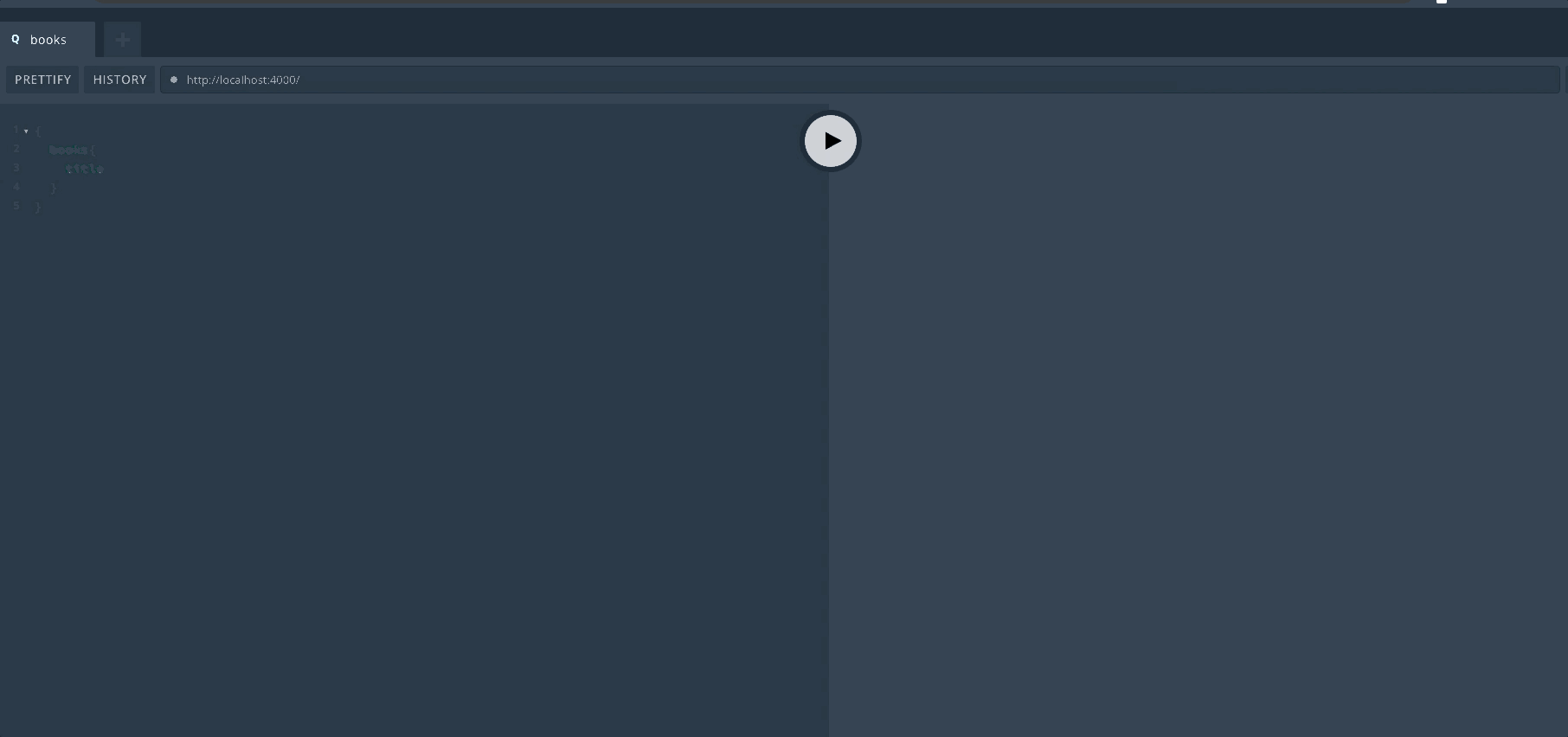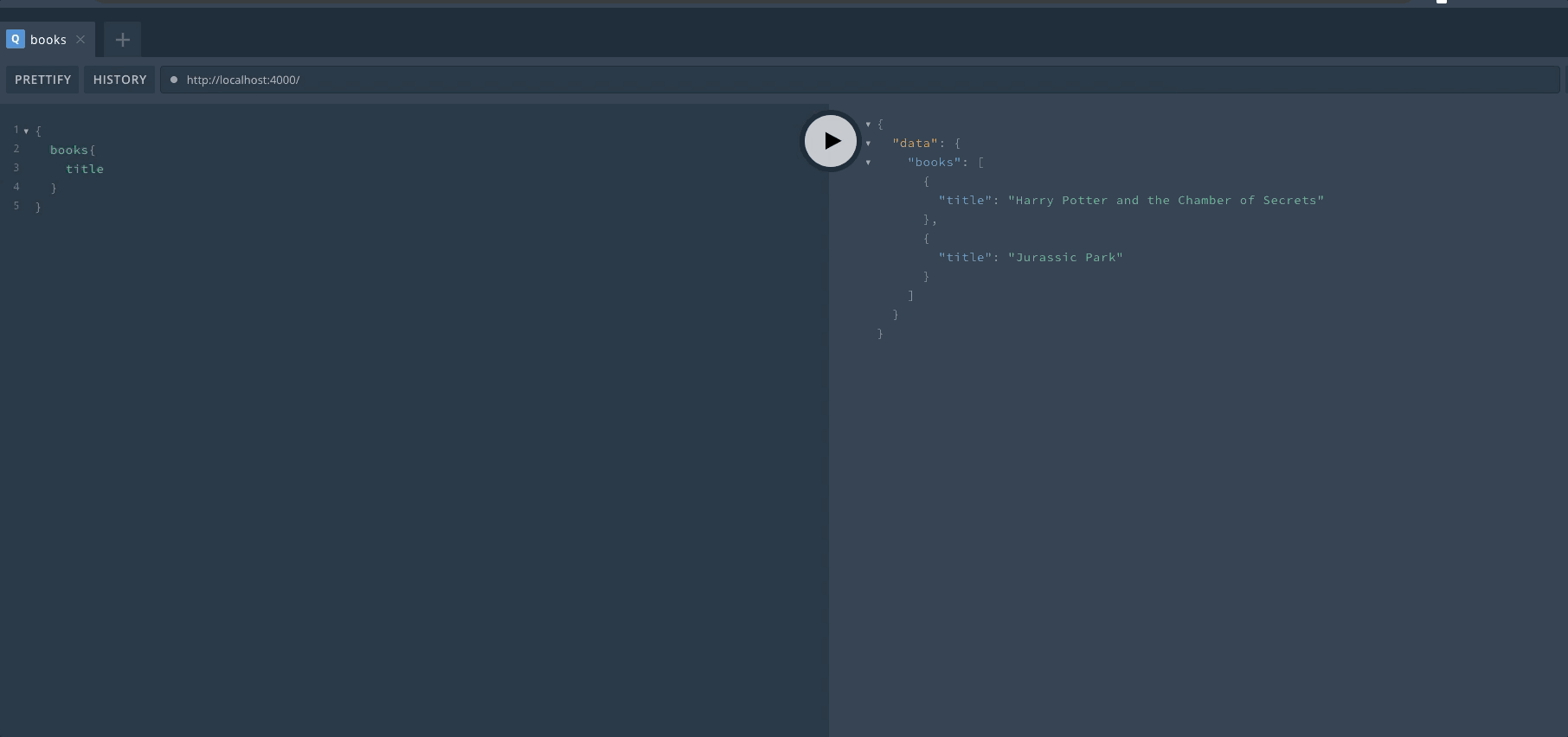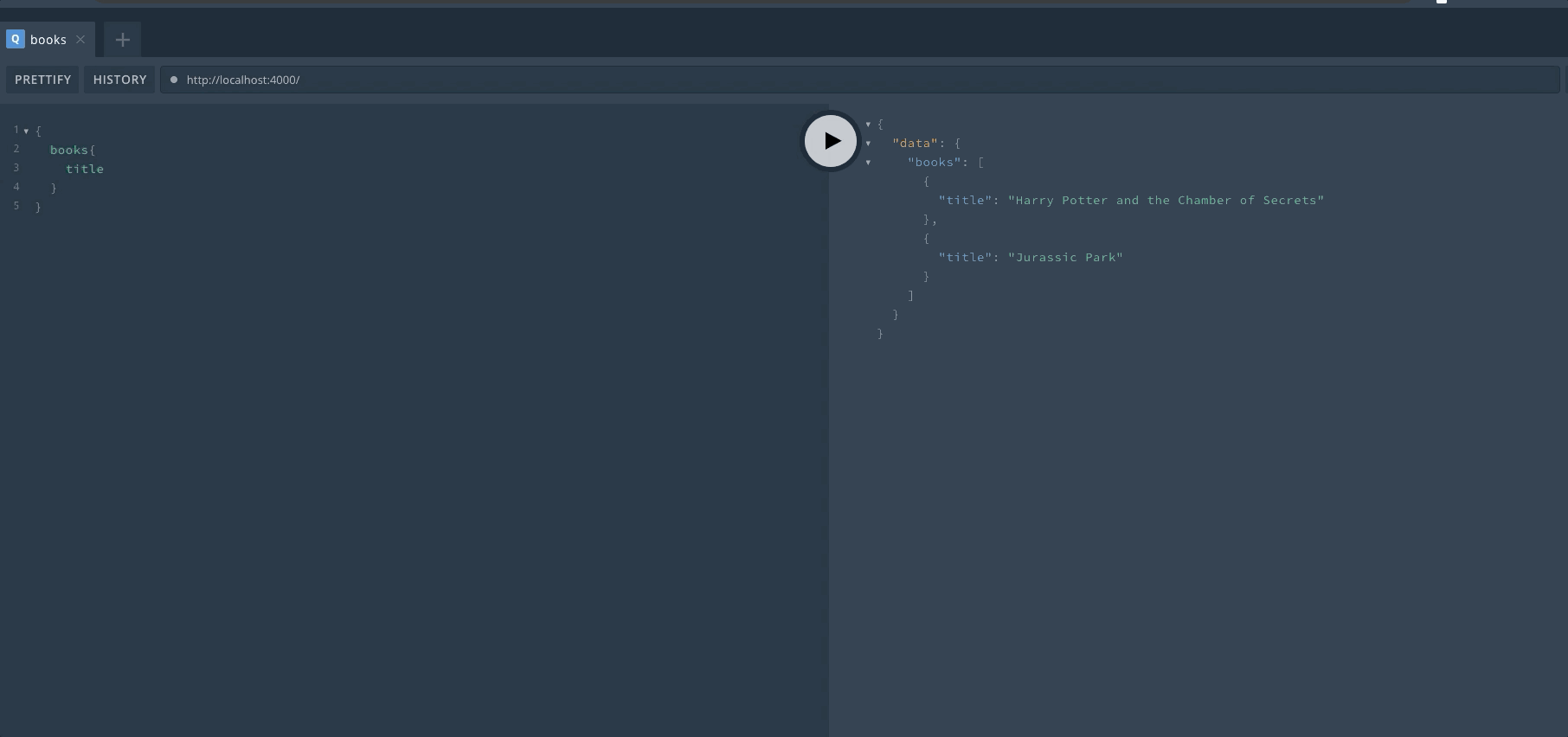
服务启动之后,我们只要访问服务器地址就可以进入 Playground 界面。我们可以在这里直接进行 GraphQL 的操作,对于上手以及调试非常有帮助。来看一下启动后的效果,左边输入 GraphQL,右边显示结果。自带代码提示,非常亲切。
GraphQL 的基本概念
梳理清楚 GraphQL 中的基本概念可以减少我们在开发中遇到的困惑。就以上面的 index.js 为例来分步拆解。
Schema 以及字段类型
GraphQL 的 Schema 规定了前端可以查询的范围,即允许查询的字段。我们可以使用 Apollo Server 提供的 gql 来包裹字符串。要注意的是,查询没有定义在 Schema 中的字段会直接会抛错。实际上前端所谓能定制字段指的也是在 Schema 范围中的字段。Schema 一般与数据库的字段关联度较高,除去前端参与 GraphQL Server 开发的情况,定义 Schema 是前后端需要互相协商的地方。
1
2
3
4
5
6
7
8
9
10
11
12
| const typeDefs = gql`
type Book{
title: String
author: String
}
type Query {
// 定义 Query 的方法和返回值
// 这里定义了 books 的方法,返回 Book 对象的数组
books: [Book]
}
`
|
可以看到上面的定义中,GraphQL 对于每个字段都有类型的要求。GraphQL 中支持的标量类型有 Int,Float,String,Boolean 和 ID 五种。对于复杂类型,常用的是 List 类型以及自定义的 type,如上面的 Book 类型。我们更常用的会是 GraphQL 内置的 Query 和 Mutation type。
关于更完整的类型支持,可以参考官方文档
Resolver 定义数据处理逻辑
Resolver 定义 GraphQL 的动作。一般业务逻辑都会放在 Resolver 里面进行处理相当于传统的 Controller 层,最后把处理后的结果返回给前端。
Schema 和 Resolver 是如何关联起来的呢?在上面的 Schema 中,type Query 中有一个对应的 books,在 type 中决定了 resolver 返回值的类型。而在 Resolver 里面则完成了具体的实现。
1
2
3
4
5
6
7
8
| const resolvers = {
Query: {
books: () => books,
}
};
|
GraphQL 中对数据的操作
Query 数据查询
关于数据的操作,GraphQL 提供了 Query 和 Mutation 两种方法,分别对应着查询与修改操作。进行这两种操作可以简单地理解为调用了对应的 resolver 方法。而对于返回值,GraphQL 也有严格的规定。如果返回的结果是一个对象类型,那么必须指定至少一个字段,不然就会报错。如果需要全部字段的话,那也只能一个个列出来,因为 GraphQL 的返回值是可预测的。
以上面的代码为例,看一下 Query 操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
| // 默认便是 Query 操作,可以省略前缀 query。但是 Mutation 操作时不能省略
query {
// 这里对应着 resolver 中的 books
// 相当于调用了 books 方法
books{
// 根据 Schema 中 Query 下 books 的定义
// 返回值是 book 对象的数组
// book 对象拥有 title 和 author 字段
// 必须要指定至少一个字段
title
author
}
}
|
可以看到在 Chrome 中的返回值和我们 query 的结构是相同的。

Mutation 数据变更
与 Query 相对应的,操作数据的方法为 Mutation。在书写上与 Query 相同,都需要在 Schema 和 Resolver 中定义好。只是在调用时必须要添加 mutation 关键字。同样再来看一个简单的例子。
首先我们在 Schema 中定义 Mutation type。在这里我们定义了一个 addBook 的方法,并且指定它的返回值为 Book 类型的 List。
1
2
3
4
5
6
7
8
| const typeDefs = gql`
// 这里与上面代码相同
...
// 定义 Mutation 的名字以及返回值
type Mutation{
addBook: [Book]
}
`
|
然后在 Resolver 中完成具体的实现。每调用一次 addBook 方法,就会往 books 数组里面插入一条数据。
1
2
3
4
5
6
7
8
9
10
11
12
| const resolvers = {
...
Mutation: {
addBook: () => {
books = [...books, { title: 'New book', author: 'New author' }]
return books
}
}
};
|
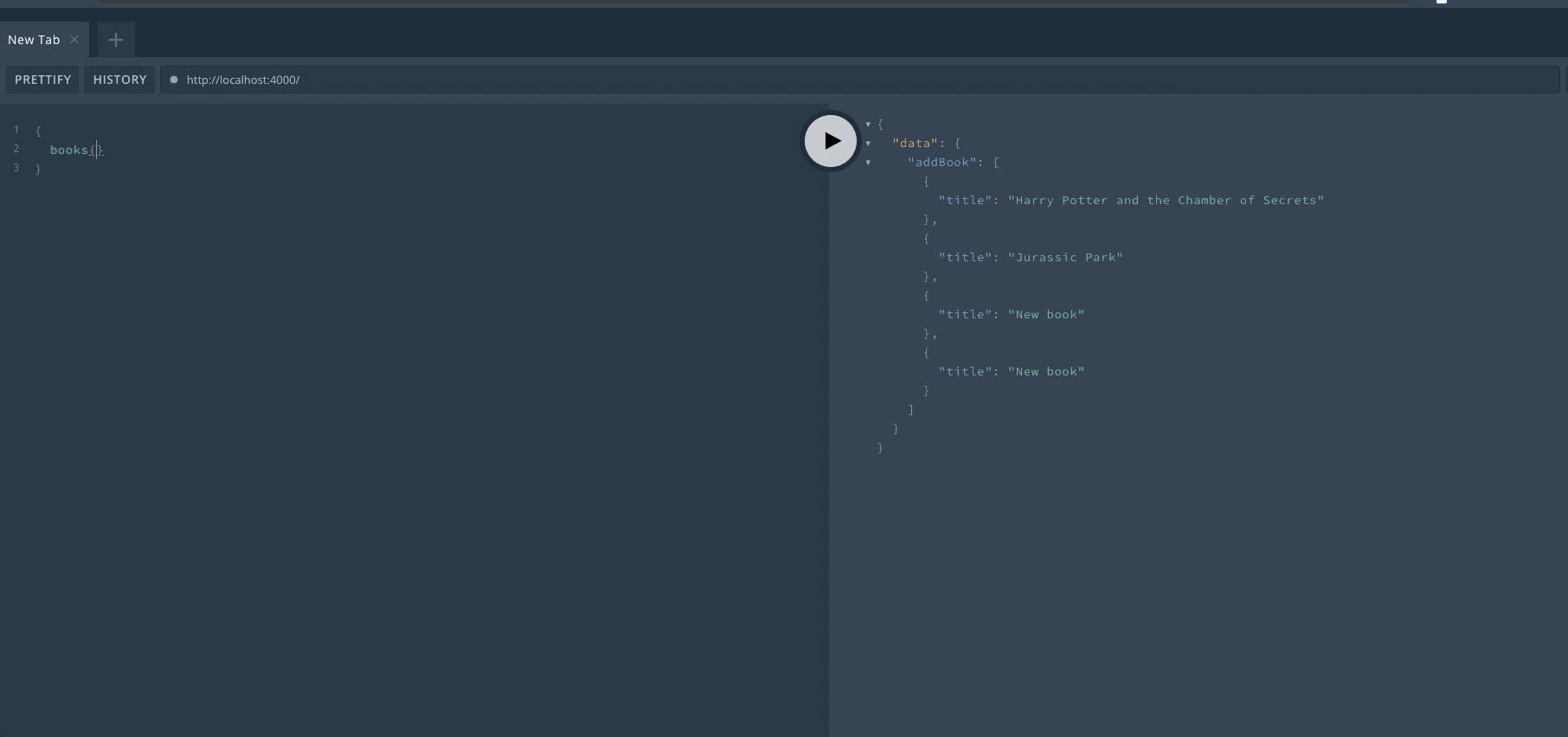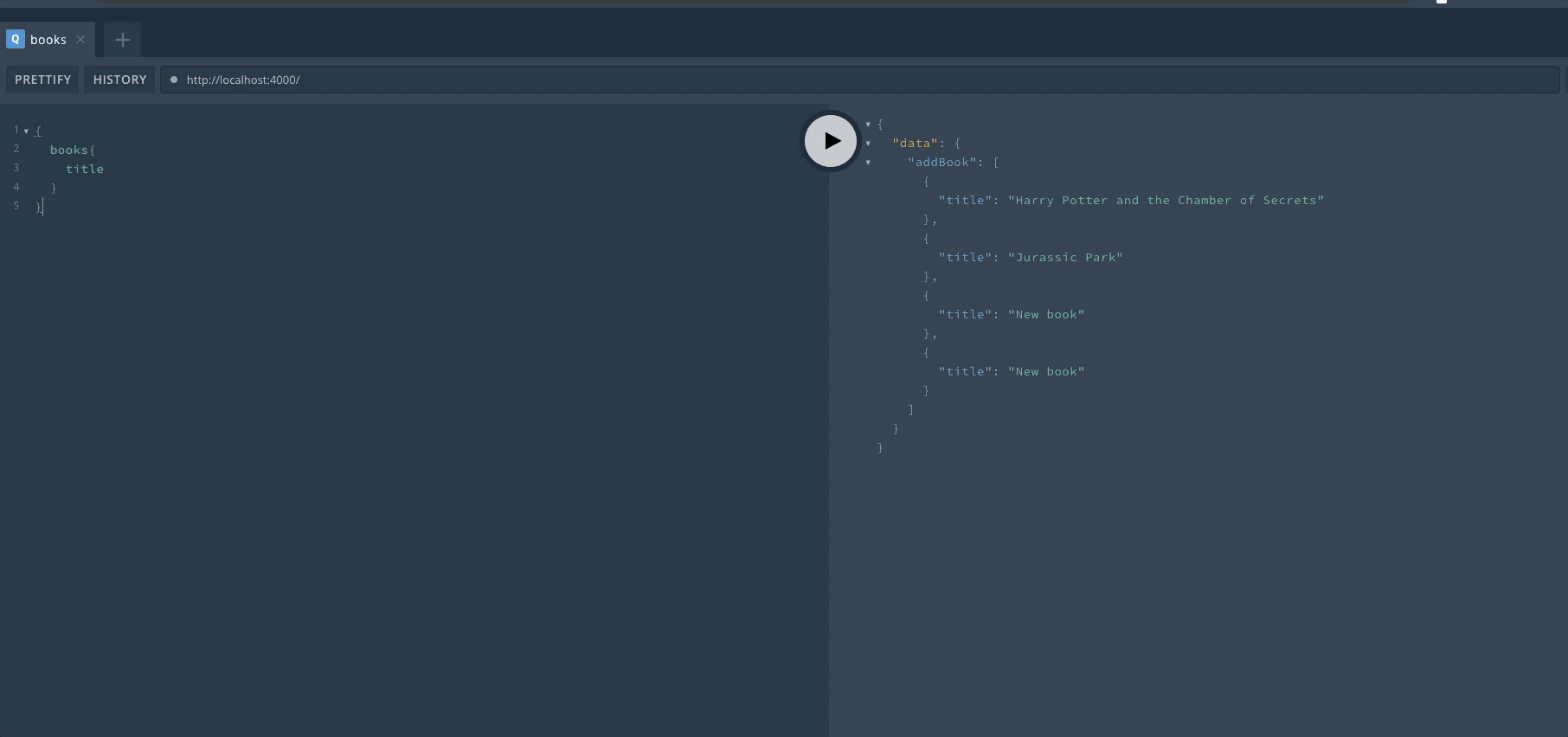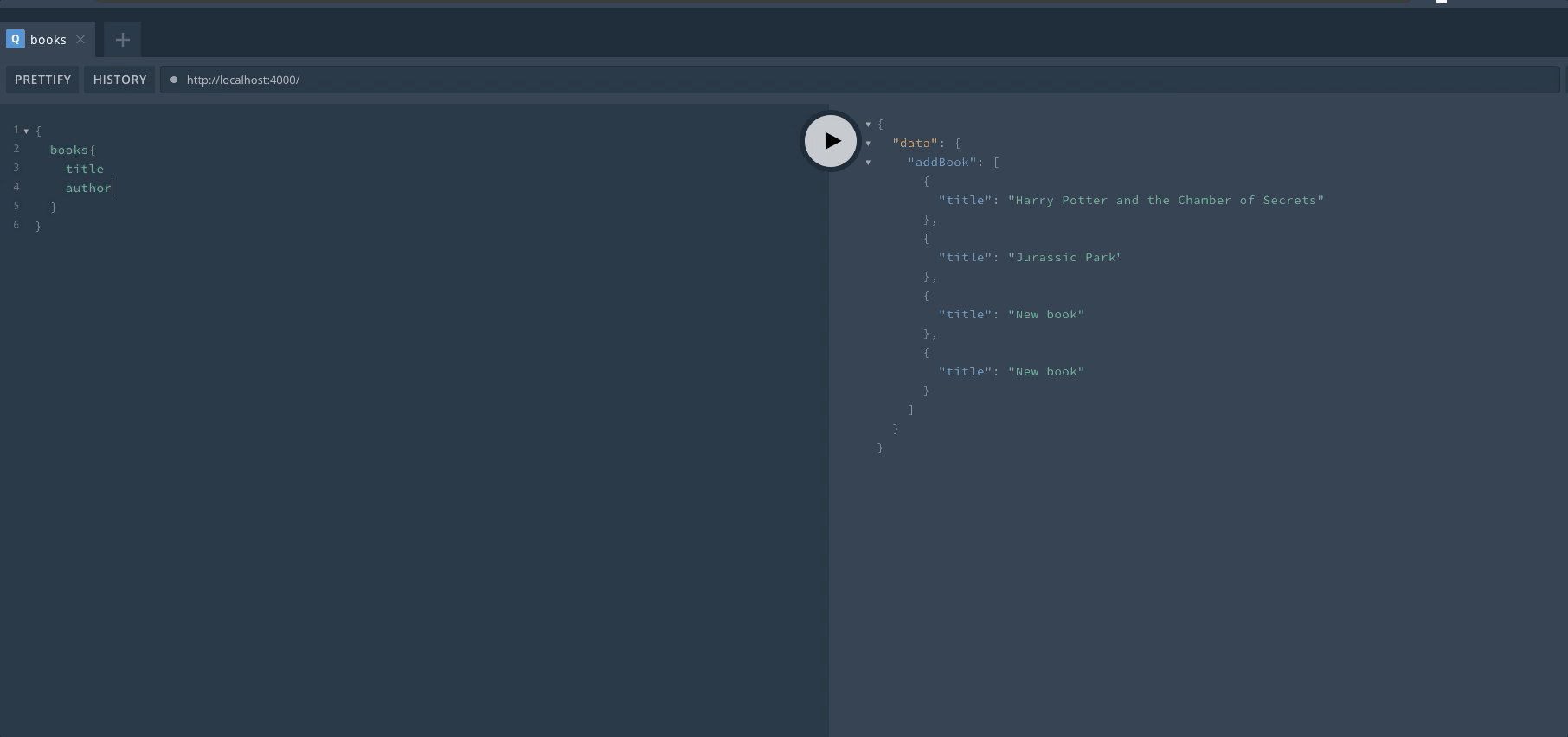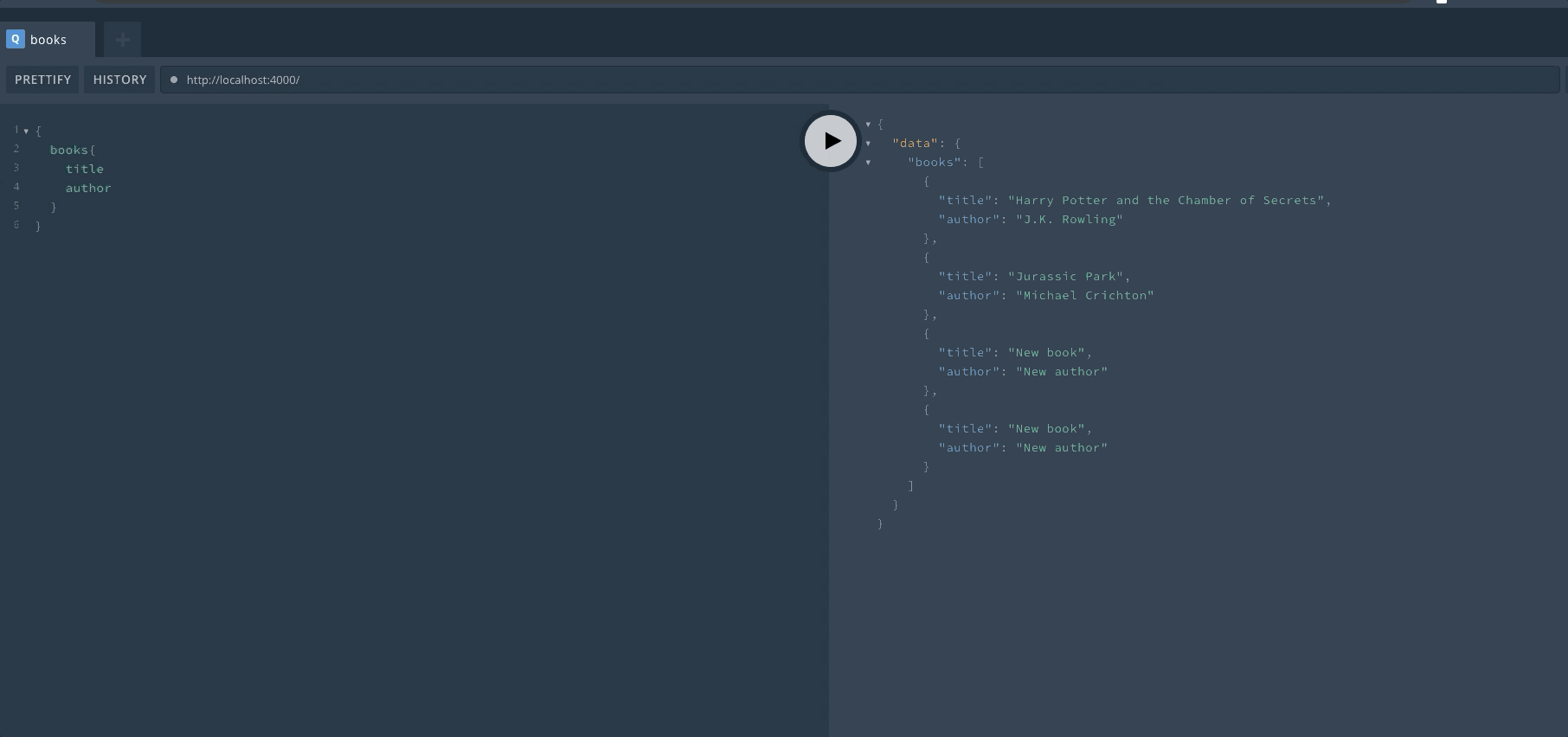
定义完成后,重启服务器然后可以在 Playground 中查看效果。首先来进行一次 Query 操作,查询是可以省略 query 关键字的。
然后我们完成一次 Mutation 操作,mutation 的关键字不能省略。在执行一次操作后,可以看到返回了新的数组。
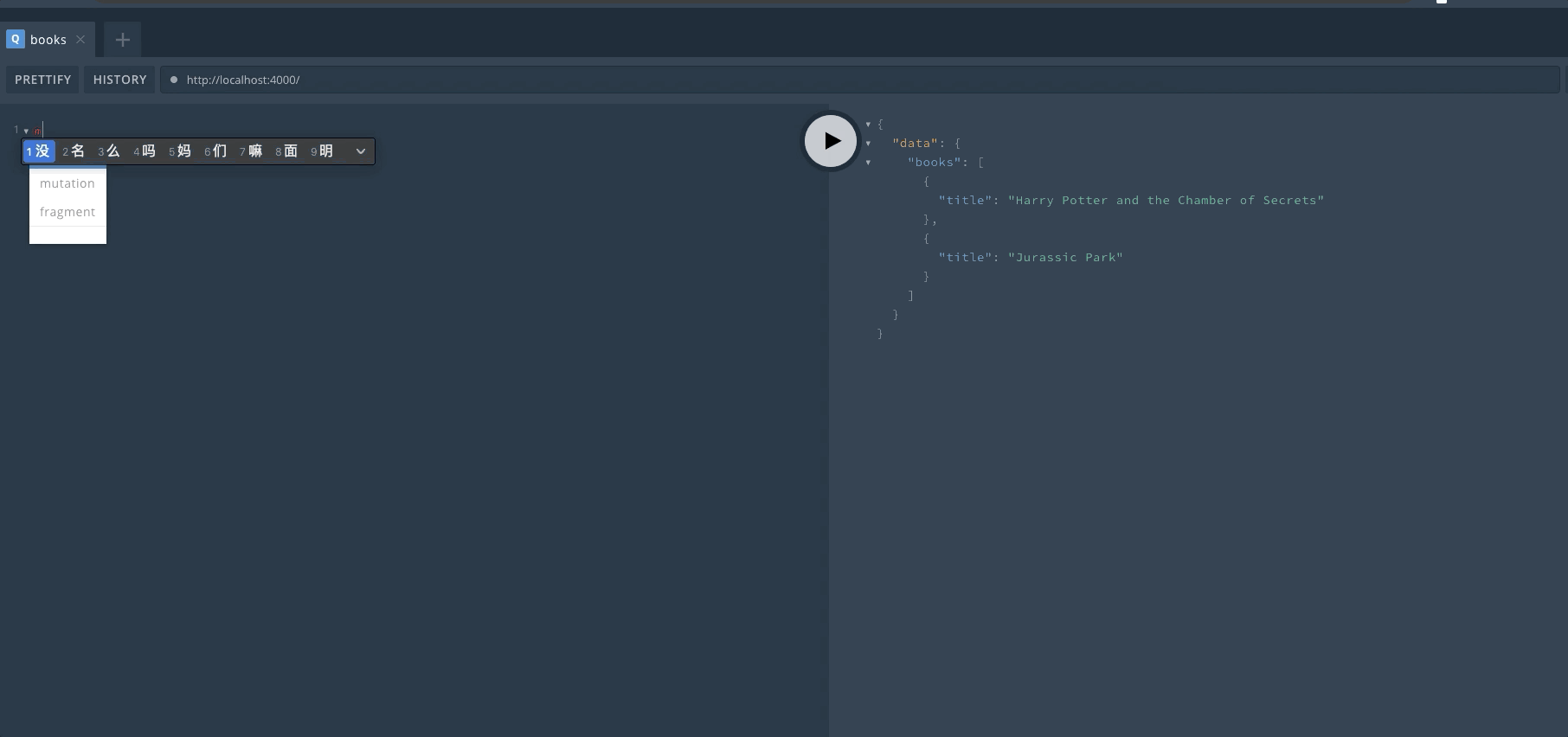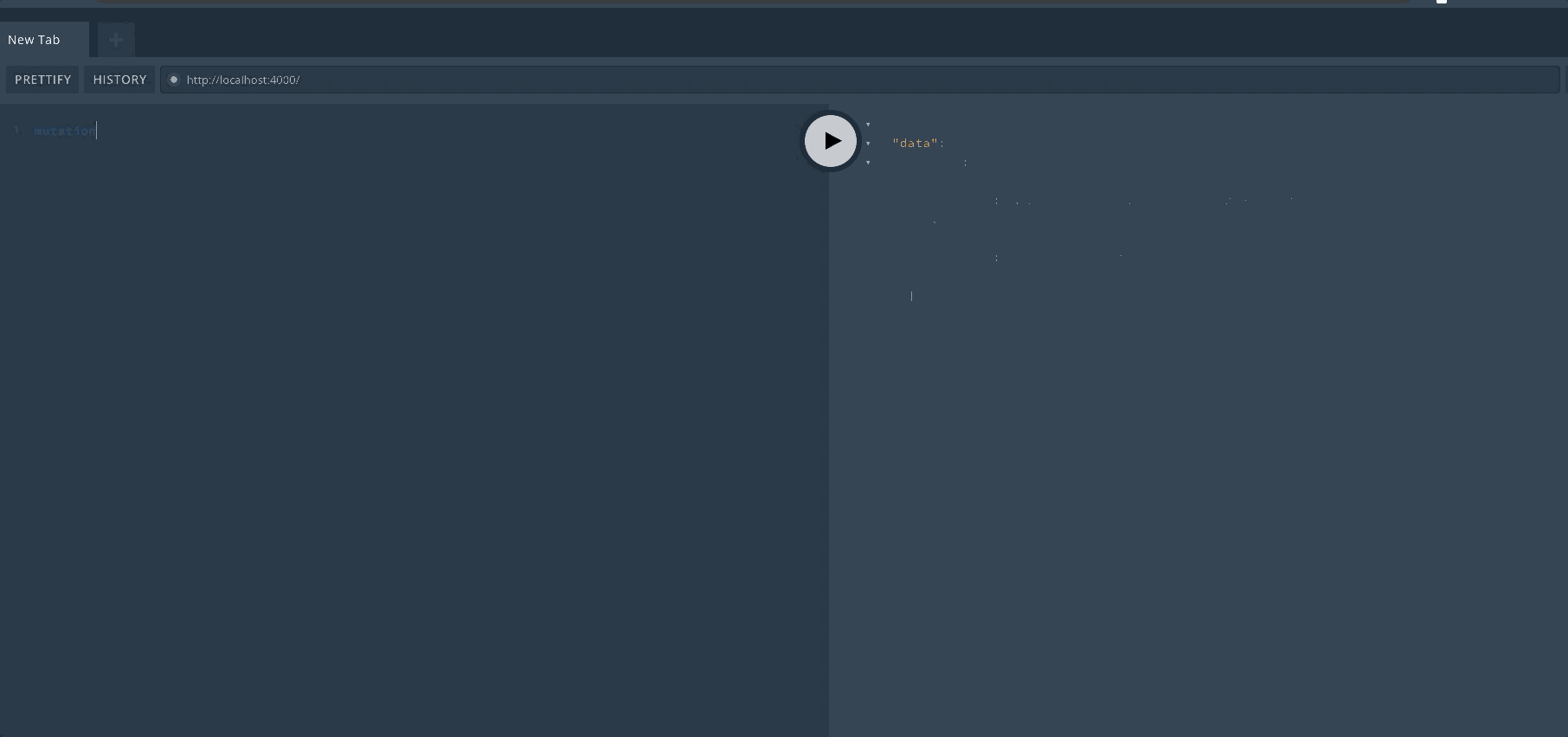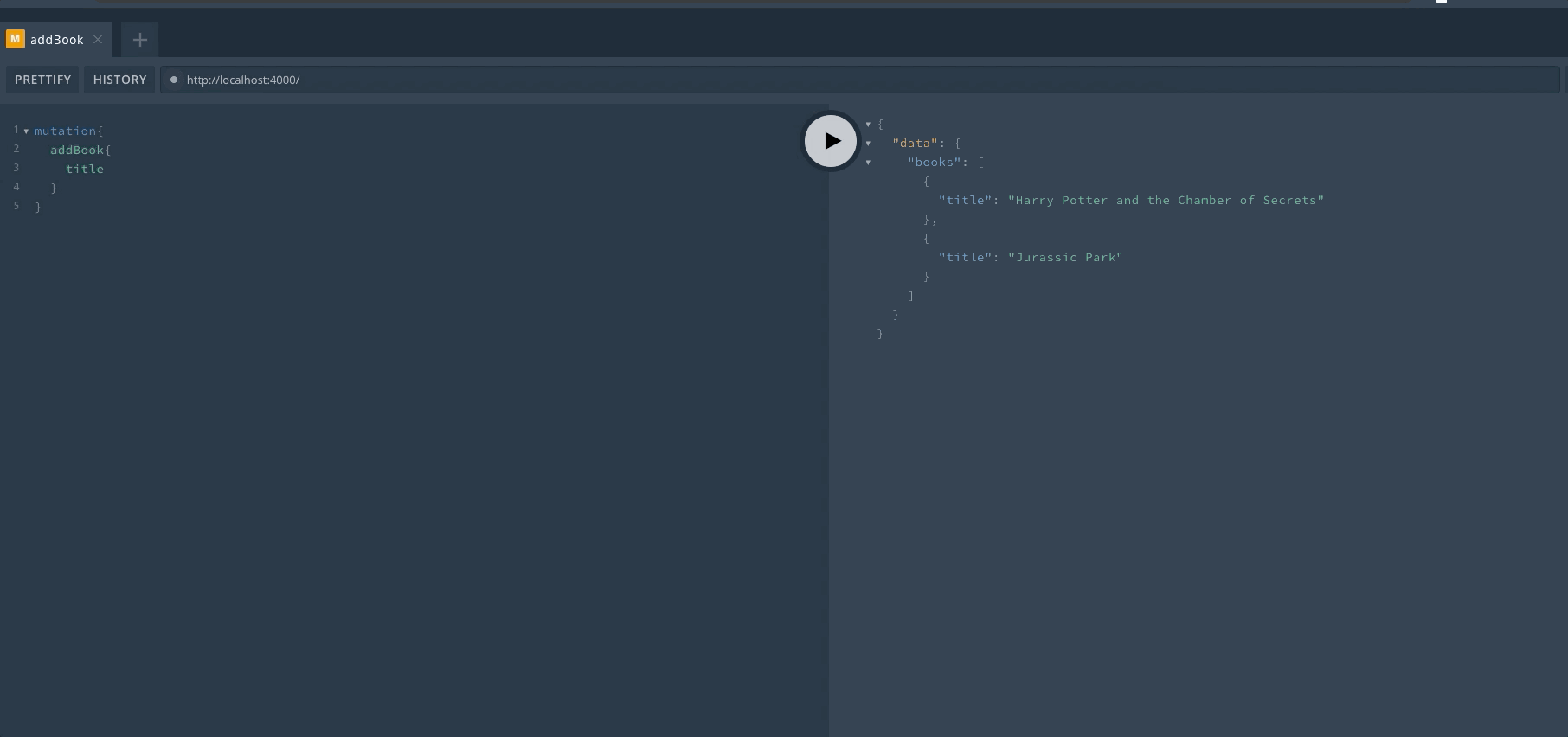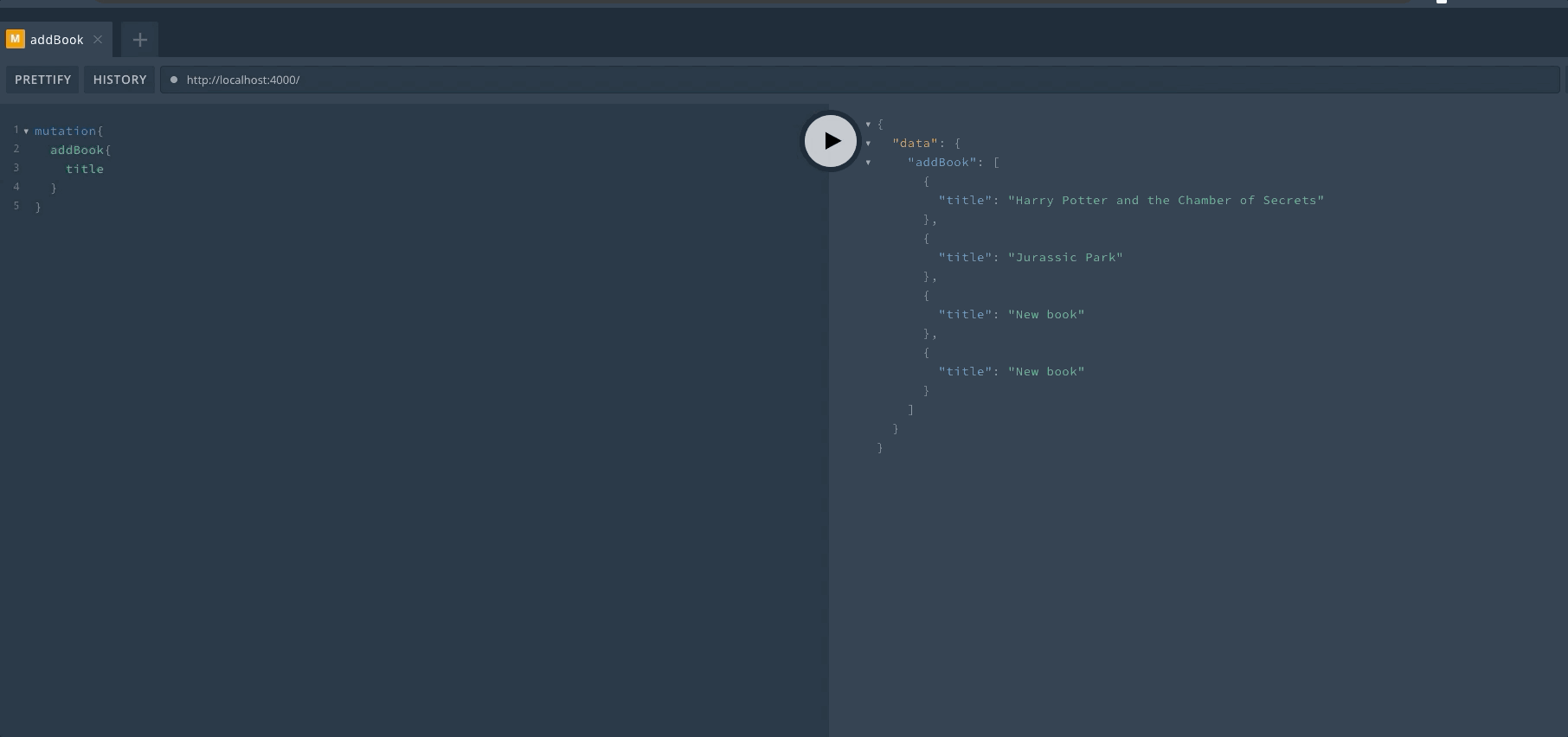
最后再来进行一次查询,可以看到数组已经发生了变化。
引入 TypeScript 以及 TypeGraphQL
GraphQL 本身的语法简单,因此很容易与 TypeScript 结合。唯一反人类的就是定义 Schema 的 gql 模版语法。这里推荐 TypeGraphQL,这个库允许我们使用 class + 装饰器的方式来定义 Schema 和 Resolver,让代码看起来更加的舒服。下面来把之前的例子用 TypeGraphQL 来重写一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import { ObjectType, Field, Resolver, Query, Mutation } from 'type-graphql'
@ObjectType()
class Book {
@Field()
title: string
@Field()
author: string
}
@Resolver(Book)
class Book {
@Query(returns => [Book])
books: () => books
@Mutation(returns => [Book])
addBook:() => {
books = [...books, { title: 'New book', author: 'New author' }]
return books
}
}
|
上面便是最基本也是最常用的写法,更多的写法以及注意点,建议去官方网站查看:typegraphql
更具体的例子
通过上面的例子,应该对 GraphQL 的概念和基本用法有一个了解。然而在实际的工作中,我们面对的情况会更加复杂。比如数据需要整合数据库,Query 和 Mutation 如果有参数改怎么做?所以下面会以之前的模板项目为例,来看一个更具体的例子。
GraphQL(TypeGraphQL) + MongoDB(TypeGoose)
模板项目使用的数据库是 MongoDB,通常 MongoDB 会使用 Mongoose 作为文档结构(表结构)的定义。在 TypeScript 的项目中,使用 TypeGoose 来代替 Mongoose。TypeGoose 同样也是使用 class + 装饰器来定义文档结构(表结构)。
鉴于 GraphQL 和 MongoDB 的 Schema 有高度的相似性。那么有聪明的小伙伴肯定猜到了,TypeGoose 与 TypeGraphQL 可以让我们不用重复定义 Schema。
以模板项目中定义 GraphQL 和 MongoDB 的 User Schema 代码为例,更多的代码可以在模板项目中查看。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
import { ObjectType, Field, ID } from 'type-graphql'
import { prop as mongooseProps, arrayProp, getModelForClass, Ref, modelOptions } from '@typegoose/typegoose'
import { Role } from './role'
@ObjectType()
@modelOptions({ schemaOptions: { collection: 'user' } })
export class User {
@Field(() => ID)
id: string
@Field()
token: string
@Field()
@mongooseProps()
username: string
@Field()
@mongooseProps()
password: string
@Field(types => [Role])
@arrayProp({ itemsRef: Role })
roles: Ref<Role>[]
@Field()
@mongooseProps({ default: Date.now })
createTime: Date
@Field()
@mongooseProps({ default: Date.now })
updateTime: Date
}
export const UserModel = getModelForClass(User)
|
在上面的例子中,导出的 class 是给 TypeGraphQL 使用,导出的 Model 就可以提供给我们进行数据库操作。如此依赖,两边的 Schema 就整合到了一起。更多关于 TypeGoose 装饰器以及参数设置,可以参考官方文档:TypeGoose
带参数的 Query 和 Mutation
上面的例子中没有带参数的例子。但实际中,传參是很常见的。那么与上面的 Schema 对应,我们来看一下 User 对应的 Resolver。这里会涉及到关于 Query 和 Mutation 的传參部分。在 TypeGraphQL 中,只要加上 @Arg 装饰器即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| import { Resolver, Query, Arg, Mutation } from 'type-graphql'
import { checkUserExist, findUserById, findUsers, createUser } from '@src/controller/user'
import { User } from '@graphql/schema/user'
@Resolver(User)
class UserResolver {
@Query(returns => Boolean, { nullable: true })
async checkUserExist(
@Arg('username') username: string,
@Arg('password') password: string
) {
return await checkUserExist({ username, password })
}
@Query(returns => String, { nullable: true })
async user(
@Arg('id') id?: string,
) {
return await findUserById(id)
}
@Query(returns => [User], { nullable: true })
async users(
@Arg('username', { nullable: true }) username?: string
) {
const condition = username ? { username } : {}
return await findUsers(condition)
}
@Mutation(returns => User)
async createUser(
@Arg('username') username: string,
@Arg('password') password: string,
@Arg('roles', type => [String], { nullable: true }) roles?: string[]
) {
return await createUser({
username,
password,
roles,
})
}
}
export default UserResolver
|
关于鉴权
实际的项目中,鉴权是绕不开的问题。GraphQL 自然也是有鉴权的。Resolver 对应的处理函数中,有一个 context 参数。在最初初始化的时候,可以绑定到 content 上然后在 resolver 中进行判断。但如此一来,鉴权的逻辑就会侵入到业务代码中。试想如果每个请求都判断是否有 token,那会是非常糟糕的一件事。
所以在模板项目中,使用了 REST 进行鉴权,比如 /login 等。有关于鉴权也可以参考官方的文章:授权
前端调用
搭建好了服务端之后,在前端调用 GraphQL 实际上非常简单。其本质和我们使用 RESTApi 一样。利用 Apollo Client 提供的 Client,就可以发送 GraphQL 的请求。
同样的,来看一下模板项目中前端部分的请求。通常我们会对 client 进行一次封装,就和我们会对 axios 进行封装一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| import { ApolloClient, ApolloLink, HttpLink, from, InMemoryCache, QueryOptions, MutationOptions } from 'apollo-boost'
import { STORAGE_KEYS } from '@constants'
import CONFIG from '@config'
const { apollo: { host, port } } = CONFIG
const httpLink = new HttpLink({
uri: `http://${host}:${port}/graphql`,
headers: {
}
})
const client = new ApolloClient({
link: from([authMiddleware, httpLink]),
cache: new InMemoryCache()
})
export const queryGQL = async ({
query,
variables = {},
}: QueryOptions) => {
try {
const { data } = await client.query({ query, variables, fetchPolicy: 'no-cache' })
return data
} catch (error) {
console.error(error)
}
}
export const mutateGQL = async ({
mutation,
variables = {}
}: MutationOptions) => {
try {
const { data } = await client.mutate({
mutation,
variables,
fetchPolicy: 'no-cache'
})
return data
} catch (error) {
console.log(error)
}
}
export default client
|
而 GraphQL 的查询语句,同样需要用 gql 进行包裹。这里的语法和我们在 Playground 中输入的语法相同,这也就是 Playground 在开发过程中的重要性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| export const GET_USERINFO = gql`
// 外层的 UserInfo 是 query 名,用于 debug
// 并且接受 userId 参数
query UserInfo($userId: String!){
// 调用 resolver 中的 userInfo 方法,接受 userId 参数
userInfo(userId: $userId){
// 定义返回的字段
nickname
avatar
phone
email
}
}
`
export const CREATE_USER = gql`
// mutation 也与 query 一样
mutation CreateUser($username: String!, $password:String!, $roles: [String!]){
createUser(username: $username, password:$password, roles: $roles){
id
}
}
`
|
GraphQL 还是 RESTful ?
小孩子才做选择,程序员要看需求
GraphQL 真的能代替 RESTful 吗?对于简单的请求来说,两者其实没有区别。
那么 GraphQL 的优势在哪呢?我觉得胜在组合与拓展性上,可以类比前端的组件化。这里拿 antd pro 的预览的首页为例。
假设每一个图表背后都有一个接口,使用 RESTful 的话,至少需要 8 个接口也就对应着 8 和请求。(实际上根据业务或者表结构,可能会更多)而 GraphQL 只需要一次请求即可。
使用 RESTful 的情况,需要请求多次
1
2
3
4
| request(总销售额请求)
request(访问量)
request(支付笔数)
request(运营活动效果)
|
使用 GraphQL 的情况,只需要请求一次
1
2
3
4
5
6
| query {
总销售额{...}
访问量{...}
支付笔数{...}
运营活动效果{...}
}
|
如果把接口整合成一个后,RESTful 在面对需求改动时修改的范围会比较大。
引用前端组件化的思想来看,在定义 GraphQL 的 Schema 时尽量原子化,然后通过前端 query 的组合来满足不同的需求。这样一来整个请求就比较灵活,并且对于后端的改动就会比较少。
参考资料
- GraphQL 官网
- Apollo Server
- 微服务下使用GraphQL构建BFF
- TypeGoose
- TypeGraphQL